Одна из самых мощных возможностей кластера виртуализации — встроенная поддержка высокой доступности (High Availability, HA). Функции HA обеспечивают отказоустойчивость виртуальных машин (ВМ) в случае выхода из строя хоста. В Proxmox эти функции встроены в кластерные возможности, однако есть нюансы, которые важно учитывать. Рассмотрим рекомендации и ошибки при работе с HA в Proxmox.
Что такое Proxmox HA?
Proxmox HA — это кластерная функция, позволяющая запускать ВМ на нескольких хостах с общим хранилищем. Если один из узлов кластера выходит из строя, ВМ, настроенные на HA, автоматически перезапускаются на работоспособном хосте.
Кроме того, это позволяет выполнять плановое обслуживание узлов без прерывания работы сервисов, устраняя необходимость в специальных окнах обслуживания.
Пример для домашней лаборатории
Даже в домашней среде можно обеспечить бесперебойную работу критических сервисов, таких как Home Assistant, медиасерверы или Git-серверы. Например, если в кластере Proxmox работают три мини-ПК, при выходе одного из них ВМ автоматически перезапустятся на оставшихся узлах.
Планирование кластера Proxmox HA
Перед развертыванием кластера учитывайте следующие требования:
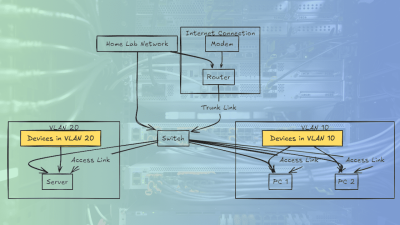
- Минимум три узла — для поддержания кворума и предотвращения split-brain (разделения кластера). Двухузловой кластер возможен с внешним устройством кворума, но три узла — рекомендованный вариант.
- Общее хранилище — NFS, iSCSI или Ceph, чтобы все узлы имели доступ к одним и тем же данным ВМ.
- Стабильная сеть — сервис corosync, отвечающий за связь между узлами, требует надежной сети с низкой задержкой. Потери пакетов могут привести к выводу узлов из кластера.
- Синхронизация времени — все узлы должны использовать единый источник времени (NTP или chrony). Расхождения во времени могут нарушить работу HA и механизма fencing.
Что нужно делать в кластере Proxmox HA
Организация ВМ в группы HA и настройка приоритетов
Группа HA — это набор ВМ или контейнеров с общими требованиями к отказоустойчивости. Группировка позволяет:
- Управлять порядком запуска (например, СУБД перед приложениями).
- Настроить антиаффинити (запрет запуска копий сервисов на одном хосте).
- Указать приоритеты восстановления.
Совет:
Создайте группы (например, critical-core для важных сервисов, low-priority для тестовых ВМ). В интерфейсе (Datacenter → HA → Groups) задайте параметры Max Relocate и Order.
Настройка fencing (изоляции узлов)
Fencing предотвращает конфликты при доступе к данным, изолируя отказавшие узлы. Без него возможен split-brain и повреждение данных.
Шаги настройки:
-
Установите агенты fencing:
apt update && apt install fence-agents
(Доступны агенты для IPMI, APC и других устройств.)
-
Добавьте устройство через GUI (Datacenter → HA → Fencing) или API:
pvesh create /nodes/
/fence —device agent=fence_ipmilan,lanplus=1,ipaddr=10.0.0.30,login=admin,passwd=secret,power_wait=10 -
Проверьте режим fencing в
/etc/pve/datacenter.cfg(watchdog,hardwareилиboth). -
Протестируйте:
pvesh create /nodes/
/fence и проверьте логи (
/var/log/syslogилиjournalctl -u pve-ha-lrm).
Мониторинг
HA не заменяет мониторинг. Отслеживайте:
- Состояние corosync (задержки, потери пакетов).
- Производительность хранилища (IOPS, задержки).
- Ресурсы хостов (CPU, RAM, сеть).
Способы реализации:
- Встроенные уведомления Proxmox (email/Slack).
- Prometheus + Grafana для сбора метрик.
Плановые тесты отказоустойчивости
Регулярно проверяйте работу HA:
- В отведенное окно отключите узел или имитируйте сбой.
- Убедитесь, что ВМ перезапускаются на других хостах.
- Проверьте логи (
/var/log/pve-ha-manager.log).
Обновление ПО кластера
Разные версии Proxmox или corosync могут нарушить работу HA.
- Обновляйте все узлы в одном окне обслуживания.
- Используйте
apt list --installed pve-cluster corosyncдля контроля версий. - Применяйте поэтапное обновление (по одному узлу).
Чего не стоит делать в кластере Proxmox HA
Ненадежная сеть для corosync
Избегайте:
- Wi-Fi или Powerline.
- Один сетевой кабель (используйте bonding).
- Разные скорости в bond (например, 1 Гбит/с и 2.5 Гбит/с).
Рекомендация: Два проводных соединения с одинаковой скоростью.
Игнорирование нагрузки на хранилище
При миграции или перезапуске ВМ растет нагрузка на хранилище. Признаки проблем:
- Зависание миграции.
- Ошибки
Timeout waiting for migration.
Протестируйте хранилище утилитой fio (задержка должна быть <10 мс).
Отключение узлов без корректировки кворума
Потеря кворума (например, 2 из 3 узлов) остановит кластер.
-
Для планового обслуживания используйте:
pvecm expected 2
- В двухузловом кластере настройте QDevice для кворума.
Перегрузка хостов
Если хосты работают на 90-100% ресурсов, они не смогут принять ВМ с отказавшего узла.
- Ограничьте число перемещаемых ВМ (
Max Relocate). - Держите запас ресурсов (~30%).
- Отслеживайте нагрузку в Resources → Summary.
Пропуск анализа логов
После сбоев проверяйте:
/var/log/pve-ha-manager.log— предупреждения о split-brain./var/log/syslog— ошибки миграции.
Итог
Proxmox HA обеспечивает отказоустойчивость ВМ, но требует правильной настройки и мониторинга. Следуя рекомендациям, вы минимизируете риски и повысите надежность кластера.